目次
はじめに
新卒で入社して気が付けば3年目に突入していたUnityクライアントエンジニアの大川です。
4か月ほど前の話ですが、上司からとあるシートを共有されました。
自分が今プログラマーとしてどのくらいのレベルがあるか知るための指標になるようです。
読み進めていくといろいろ自分に足りない知識が多いと痛感させられました。
その中で、「アセンブリコードを読むことが出来る」という文章がありまして、
今まで読むことも使うこともないとスルーしてきた分野であったため、この機会に少し勉強してみようと思いました。
業務でもプライベートでも使用している64bit IntelCpuのアセンブリコードをC言語から出力して、実際に解読して行きたいと思います。
本記事が、アセンブリを知るきっかけになっていただけると幸いです。
アセンブリコードとは
実行ファイルは機械語の2進数の羅列で、人間が読んでも良くわかりません。
アセンブリは二進数の命令を人間が読める文字と記号で表現されているため、
アセンブリを書いて機械語に変換をかければCPUに直接命令を出すことが出来ます。
しかし、メモリ・ポインター・アドレスの概念をC言語以上に意識しなければならないため、
実現したいロジック以外に考えることが多くてロジックに集中しにくく、生産性が悪くなります。
そのため、C/C++言語でロジックを考えてそこから先はコンパイラに任せるのが一般的です。
命令はCPUによって異なるので、アセンブリコードもCPUによって変わります。
実行・確認環境
DockerでUbuntuのコンテナを建てて、コードをコンパイルして確認していきます。
こちらがアセンブリコードを読むために作成したリポジトリです。
Dockerの実行方法に関しては、リポジトリのREADMEをご参照ください。
workディレクトリ配下に、検証するカテゴリでディレクトリを分けて、
その中にMakefile・Cコード・アセンブリコード・実行ファイル・README(メモ用)が入っています。
Makefileで二つのタスクを用意しています。
|
1 2 3 4 5 6 7 8 9 10 11 |
cc = gcc fileName = stack build: $(CC) -fno-asynchronous-unwind-tables -S $(fileName).c $(CC) -o $(fileName) $(fileName).c -g assemble: as -o $(fileName).o $(fileName).s gcc -o $(fileName) $(fileName).o |
|
1 |
make build |
こちらでCコードからアセンブリコードと実行ファイルを生成します。
|
1 |
make assemble |
こちらはアセンブリコードから実行ファイルを生成して、
アセンブリコードを直接編集して動作を確認するために使用します。
レジスタ
アセンブリを読み進めていく上で、一時的に値を保存するためのレジスタが頻繁に登場します。
レジスタには色々種類や役割がありまして、こちらに分かりやすくまとめられていたので、
参照しつつ本記事を読み進めていただければと思います。
Hello World
まずは基本のHelloWorldです。
|
1 2 3 4 5 6 |
#include <stdio.h> int main() { puts("HelloWorld"); return 0; } |
こちらをアセンブリコードにするとこちらになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
.file "hello.c" .text .section .rodata .LC0: .string "HelloWorld" .text .globl main .type main, @function main: endbr64 pushq %rbp movq %rsp, %rbp leaq .LC0(%rip), %rdi call puts@PLT movl $0, %eax popq %rbp ret |
今回注目する箇所はこちらです。
|
1 2 3 4 5 6 7 8 9 |
-- .LC0: .string "HelloWorld" -- main: -- leaq .LC0(%rip), %rdi call puts@PLT -- |
まずわかることは、実行ファイルの中に”HelloWorld”が直接入るようです。
leaqは
指定されたアドレスから64bitを指定されたレジスタに読み込む命令で、
“HelloWorld”の先頭アドレスをrdiレジスタに格納しているように見えます。
leaはLeadでqは64bitを示しています。
.LC0(%rip)
.LC0はラベルといってそれ以下のデータの場所を表すアドレスです。
ripレジスタは実行場所のアドレスを保持するもので、インストラクションポインタと呼ばれています。
インストラクションポインタからどのくらい後ろのアドレスに”HelloWorld”が格納されているかを表しています。
そしてそのあとに
call puts@PLT
で、文字出力する処理が書かれているアドレスに実行場所をジャンプさせています。
(putsの中身には触れないことにしましょう)
関数の第一引数はrdiレジスタに格納するというルールがありまして、
ジャンプした先でもrdiレジスタを見て文字を出力します。
関数について
関数がアセンブラではどのように扱われているか見ていきます
引数
まずは引数です。
こちらのシンプルな関数のアセンブリコードを見たいと思います。
|
1 2 3 4 5 6 7 8 |
int sum2(int a, int b) { return a + b; } int main() { printf("%d", sum2(1,2)); return 0; } |
sum2の中身がこちらで
|
1 2 3 4 5 6 7 8 9 |
sum2: pushq %rbp movq %rsp, %rbp movl %edi, -4(%rbp) movl %esi, -8(%rbp) movl -4(%rbp), %edx movl -8(%rbp), %eax addl %edx, %eax popq %rbp |
呼び出しはこちらになっています
|
1 2 3 |
movl $2, %esi movl $1, %edi call sum2 |
呼び出し元を見ると、第一引数はedi、第二引数はesiに格納するみたいです。
関数の中では、
|
1 2 3 4 |
movl %edi, -4(%rbp) movl %esi, -8(%rbp) movl -4(%rbp), %edx movl -8(%rbp), %eax |
一度メモリに格納して、メモリから再度読み込んで値を利用しています。
(rbpレジスタについては、後ほど触れます)
movl %edi, -4(%rbp)
movlは4バイトの値をコピーする命令で
rbpレジスタが指すアドレスの4バイト後ろから4バイトの領域にediの中身をコピーするという意味になります。
関数内でさらに関数を呼び出す場合、
引数を渡すために、edi,esiを利用するのでデータが失われてしまうためメモリに格納しています。
そして最後に
addl %edx, %eax
addlは4バイトの値を加算する命令で、eaxに対してedxの値を加算しています。
プログラムの式で表すと、こちらと同じ意味になります。
eax += edx
また、eaxレジスタには戻り値を格納するというルールがあります。
スタック
関数で使用される、スタック領域について詳しく見ていきましょう。
先ほどのsum2関数を再度例にあげます。
|
1 2 3 4 5 6 7 8 9 |
sum2 pushq %rbp movq %rsp, %rbp movl %edi, -4(%rbp) movl %esi, -8(%rbp) movl -4(%rbp), %edx movl -8(%rbp), %eax addl %edx, %eax popq %rbp |
スタックを操作するために2つのレジスタが登場します
rbp ベースポインタ
rsp スタックポインタ
関数の先頭の
|
1 2 |
pushq %rbp movq %rsp, %rbp |
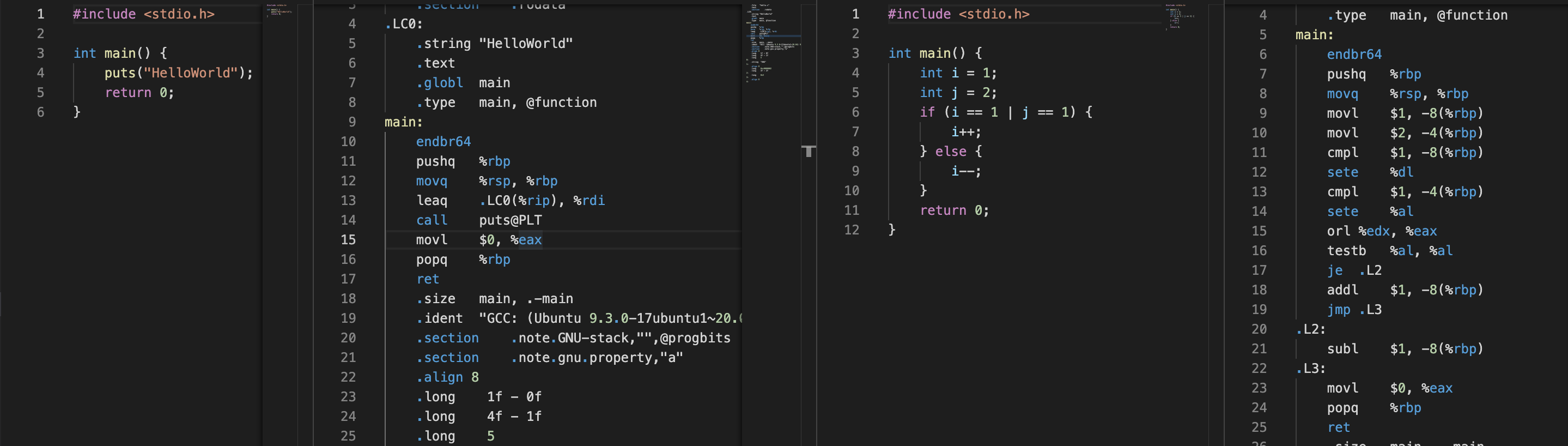
は、
pushqでベースポインタの中身8バイトをスタックポインタに積んで、
スタックポインタのアドレスが8バイト移動し、
movqでスタックポインタの中身をベースポインタにコピーしています。
図示化すると以下のようになります。
領域の確保は、スタックという言葉とは逆で下方向に確保するので、図のような書き方になっています。
メモリとレジスタは別々なので、
rspをrbpにコピーした後は、メモリ内のrbpは古い値になりますね。
しかし、8バイトの容量しか確保していないので、これを超える場合はどうなるのでしょうか?
こちらの場合を見てみましょう。
|
1 2 3 4 5 6 7 |
int sum(int a, int b) { return a + b; } int sum2(int a, int b, int c) { return sum(a, b); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
sum: pushq %rbp movq %rsp, %rbp movl %edi, -4(%rbp) movl %esi, -8(%rbp) movl -4(%rbp), %edx movl -8(%rbp), %eax addl %edx, %eax popq %rbp ret sum2: pushq %rbp movq %rsp, %rbp subq $16, %rsp movl %edi, -4(%rbp) movl %esi, -8(%rbp) movl %edx, -12(%rbp) movl -8(%rbp), %edx movl -4(%rbp), %eax movl %edx, %esi movl %eax, %edi call sum leave ret |
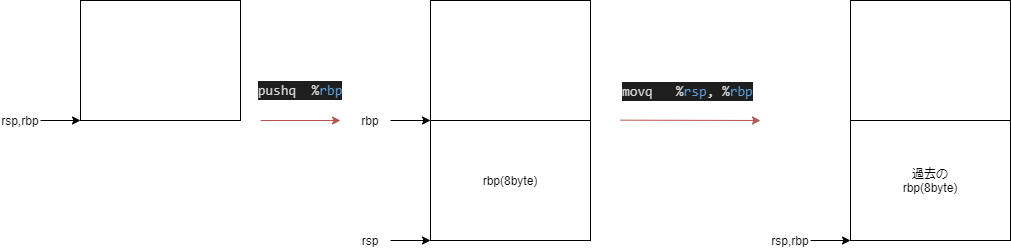
sum2の中に
subq $16, %rsp
でスタックポインタの示す場所をを16バイト下げていますね。
図示するとこちらになります。
スタックポインタの位置を変更することで、次に容量を確保するときに使用した領域と被らないようにしています。
ret命令で、スタックポインタとベースポインタを一つ前の位置を指すようにしていると読み取れます。
図を見ていただけると分かりますが、過去のベースポインタのアドレスはメモリ上に保存されているので、
それをスタックポインタとベースポインタにコピーする処理がretで行われていると思います。
引数が多い時
レジスタの数には限りがあるので、引数の数にも限界があるように見えてきますが、どのようにして対応しているのか見てみましょう。
|
1 2 3 4 5 6 7 |
int many_sum(int a, int b, int c, int d, int e, int f, int g, int h) { return a + b + c + d + e + f + g + h; } int func() { return many_sum(1,2,3,4,5,6,7,8); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
many_sum: pushq %rbp movq %rsp, %rbp movl %edi, -4(%rbp) movl %esi, -8(%rbp) movl %edx, -12(%rbp) movl %ecx, -16(%rbp) movl %r8d, -20(%rbp) movl %r9d, -24(%rbp) movl -4(%rbp), %edx movl -8(%rbp), %eax addl %eax, %edx movl -12(%rbp), %eax addl %eax, %edx movl -16(%rbp), %eax addl %eax, %edx movl -20(%rbp), %eax addl %eax, %edx movl -24(%rbp), %eax addl %eax, %edx movl 16(%rbp), %eax addl %eax, %edx movl 24(%rbp), %eax addl %edx, %eax popq %rbp ret func: pushq %rbp movq %rsp, %rbp pushq $8 pushq $7 movl $6, %r9d movl $5, %r8d movl $4, %ecx movl $3, %edx movl $2, %esi movl $1, %edi call many_sum addq $16, %rsp leave ret |
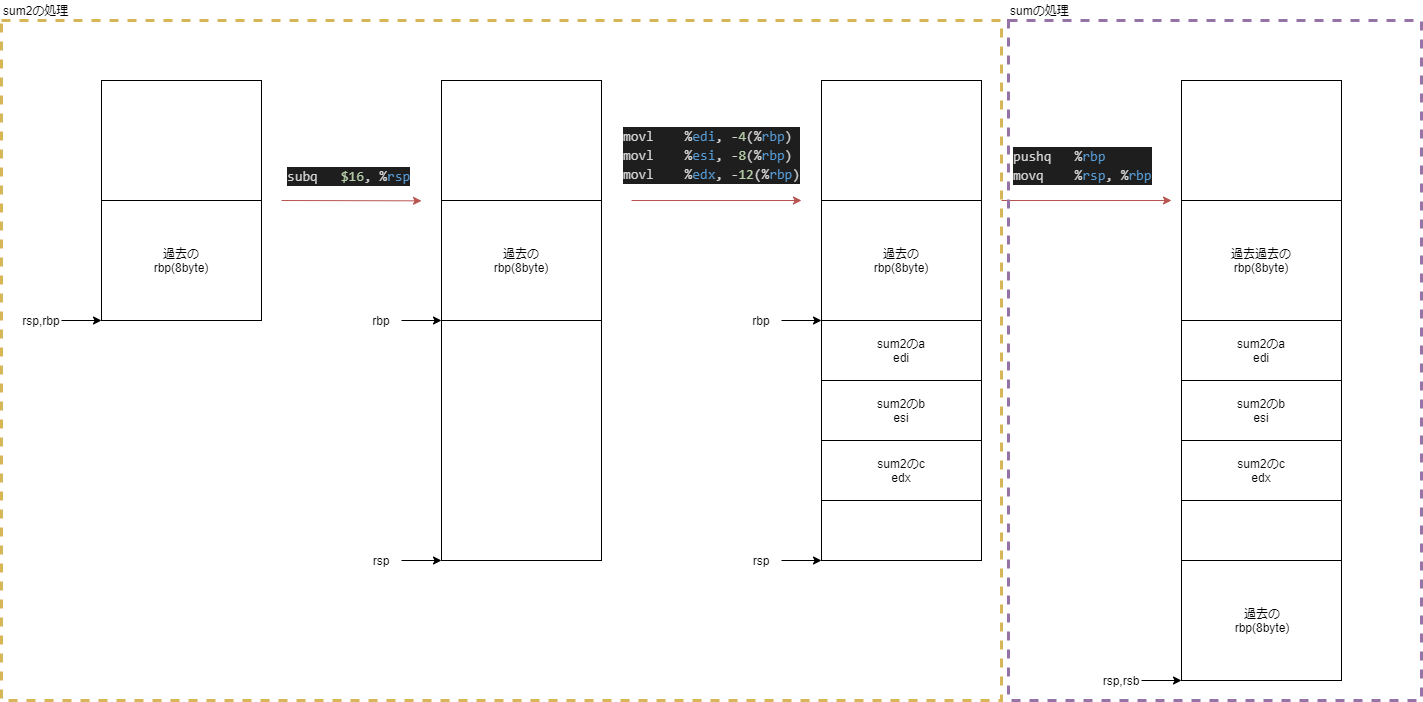
こちらを確認すると、
|
1 2 3 4 5 6 7 8 |
pushq $8 pushq $7 movl $6, %r9d movl $5, %r8d movl $4, %ecx movl $3, %edx movl $2, %esi movl $1, %edi |
7個目の引数からレジスタにコピーすることをやめて、スタックに直接積んでますね。
movl 16(%rbp), %eax
そしてアクセスするときはベースポインタの上を見るようになってます。
図示して流れを整理してみました。
図示してみると、ベースポインタより下のアドレスは上方向、
ベースポインタより上のアドレスは下方向に領域を見るようになっているようです。
条件分岐
プログラムの基本の条件分岐を見てみます。
見てみるコードがこちらです。
|
1 2 3 4 5 6 7 8 9 |
int main() { int i = 1; if (i == 1) { i++; } else { i--; } return 0; } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
main: pushq %rbp movq %rsp, %rbp movl $1, -4(%rbp) cmpl $1, -4(%rbp) jne .L2 addl $1, -4(%rbp) jmp .L3 .L2: subl $1, -4(%rbp) .L3: movl $0, %eax popq %rbp ret |
cmpl $1, -4(%rbp)
こちらで
if (i == 1)
の比較を行っています。
比較結果はフラグレジスタに保存されて次の行でフラグレジスタを見てジャンプするかどうかを決めているようです。
jne .L2
こちらの命令はおそらく、Jump If Not Equalの略で
ジャンプ先のL2で減算処理をしていることから、コードのelse文に飛んでいることが分かります。
条件を満たしている場合は、ジャンプせず次の行の
addl $1, -4(%rbp) で加算処理を行った後、
jmp .L3でL3にジャンプしてMain関数のリターン処理を行っています。
ここから条件を変えていろいろ見ていきます。
条件を i !=1に変えてみると、
je .L2
に変わりました。
Jump If Equalですね。
i >= 1
jle .L2
Jump If Less Equal
i <= 1
jg .L2
Jump If Greater
イコールを外して、i > 1, i < 1にして、
アセンブリコードを確認してみたところジャンプ命令は同じでした。
jge = Jump If Greater Equal と jl = Jump If Less 命令はあるのか気になったので、
出力されたアセンブリを上記の命令に変更して実行ファイルを出力してみたところ、
正常に動作したので2つの命令も存在しているようです。
次に論理積を見ていきましょう。
|
1 2 3 |
if (i == 1 && j == 1) { //-- } |
|
1 2 3 4 |
cmpl $1, -4(%rbp) jne .L2 cmpl $1, -8(%rbp) jne .L2 |
&&は、一つ目の条件を満たさなかった場合、次の比較は行わないので、アセンブリもそのままですね。
&に変えてみるとどうなるでしょう?
|
1 2 3 4 5 6 7 8 9 10 |
int main() { int i = 1; int j = 2; if (i == 1 & j == 1) { i++; } else { i--; } return 0; } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
main: pushq %rbp movq %rsp, %rbp movl $1, -8(%rbp) movl $2, -4(%rbp) cmpl $1, -8(%rbp) sete %dl cmpl $1, -4(%rbp) sete %al andl %edx, %eax testb %al, %al je .L2 addl $1, -8(%rbp) jmp .L3 .L2: subl $1, -8(%rbp) .L3: movl $0, %eax popq %rbp ret |
やっていることが結構変わりました、
cmpl $1, -8(%rbp)
こちらで、i == 1を比較し、
sete %dl
sete = Set Equal 比較した結果がtrueである場合、指定されたレジスタに値1をセットして、falseの場合は0をセットする命令です。
そのあとも同様の処理をして、
i == 1の結果が dl
j == 1の結果が al
に格納されるので、
dl = 00000001
al = 00000000
になりますね。
dlはedxの下1byteの領域、alはeaxの下1byteの領域で、

andl %edx, %eax
こちらでedxとeaxの&演算を行い、
testb %al, %al
test命令は、2オペランドの論理積を行った結果で、フラグレジスタにフラグを立てます。
今回のプログラムの場合は0になりますね。
そして次の命令
je .L2
で等しい場合はL2にジャンプします。
L2は減算処理なので、elseの部分にあたります。
i == 1 & j == 1
の結果は0で、elseにジャンプするのですが、
アセンブリは等しいとelseにジャンプするという意味になっています。
つまり、cpuは0=equal, 1=not equalで扱っているように見えます。(紛らわしいですね)
論理和の場合、条件が反転してor演算に変わるだけで、動きは同じでした。
ループ
次にループ処理ですが、条件分岐とジャンプで実現されています。
なので、基本は条件分岐と変わりません。
Cコード
|
1 2 3 4 5 6 7 |
int main() { int sum = 0; for (int i = 1; i <= 10; i++) { sum += i; } return 0; } |
アセンブリコード
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
main: pushq %rbp movq %rsp, %rbp movl $0, -8(%rbp) movl $1, -4(%rbp) jmp .L2 .L3: movl -4(%rbp), %eax addl %eax, -8(%rbp) addl $1, -4(%rbp) .L2: cmpl $10, -4(%rbp) jle .L3 movl $0, %eax popq %rbp ret |
まとめ
基本的な処理のアセンブリコードを解読してみました。
アセンブリコードを読むことで、プログラミング言語のその先の処理が見えて面白いなと思いました。
今回はC言語でしたが、C++のclassはアセンブリコードでどのように表現されているのか見てみるのも新しい発見がありそうです。


