
こんにちは!
普段はクライアントエンジニアしているやっすんです!
今回はTauri(rust)と形態素解析を使って開発便利ツールを作成したのでその技術紹介(後半)です!
この記事では形態素解析の解説を行います!
目次
前編の振り返り
前編の記事ではツールを作成することになった背景と、ツールの構成について説明しました。
またtauri側ではプロジェクトの作成~ビルドまでを一通り解説しています。
先に前編をご覧になることをおすすめします!
形態素解析とは
この記事の本編である形態素解析について説明です。
形態素解析を一言で説明すると、
「文章を意味のわかる最小単位まで分解して、それらの品詞(名詞や動詞、形容詞など)を解析する」
です。
形態素解析では、単語レベルで分解した上でそれぞれの品詞を解析・分類し、文の構成や自然言語処理などの研究でよく使用されています。
今回使用する、スキルの説明文とマスタの例としては下のようになっています。
- 敵全体に水属性の攻撃(威力:180)を行う
- 味方全体に、防御力強化(効果:30)を行う
- 自分に、攻撃力強化(効果:200)を行い、3ターン混乱状態にする
| スキルID1 | ターゲット | 属性 | 効果値 | スキルID2 | ターゲット | 属性 | 効果値 |
| 攻撃 | 敵全体 | 水 | 180 | – | – | – | – |
| 防御力強化 | 味方全体 | – | 30 | – | – | – | – |
| 攻撃力強化 | 自分 | – | 200 | 混乱状態付与 | 自分 | – | 3 |
敵全体に水属性の攻撃(威力:180)を行う
この文章を形態素ごとに分割すると、
敵/全体/に/水/属性/の/攻撃/(/威力/:/180/)/を/行う/
と分解することができると思います。
ここから不要な文字(接続詞)を削除して解析しやすいように編集します。
敵/全体/水/属性/攻撃/威力/180/
接続詞などを削除するとこのようになります。これならプログラム側で制御できそうですね。
ちなみにですが、接続詞などの削除はバックエンドのrust側で行なっています。
品詞分解した値は配列として返却されるため、削除する文字のリスト(解析には不要な文字のリスト)を持っておき一致した場合には配列から削除するようにしています。
JavaScriptでの形態素解析
今回使用するライブラリはTinySegmenterです。
このライブラリは品詞解析まではできないのですが、非常に軽量で高速に分かち書き後行ってくれます。また辞書等は持っておらずサーバとの通信も不要で、このライブラリ単体で実行可能という利点があります。
他の形態素解析ライブラリでは品詞分解という、分割した形態素がどの品詞かという解析も可能なライブラリもありますが、今回は品詞の情報は不要なため、分かち書きで十分です。
試しに、配布サイトで精度の確認を行ってみます。
敵/全体/に/水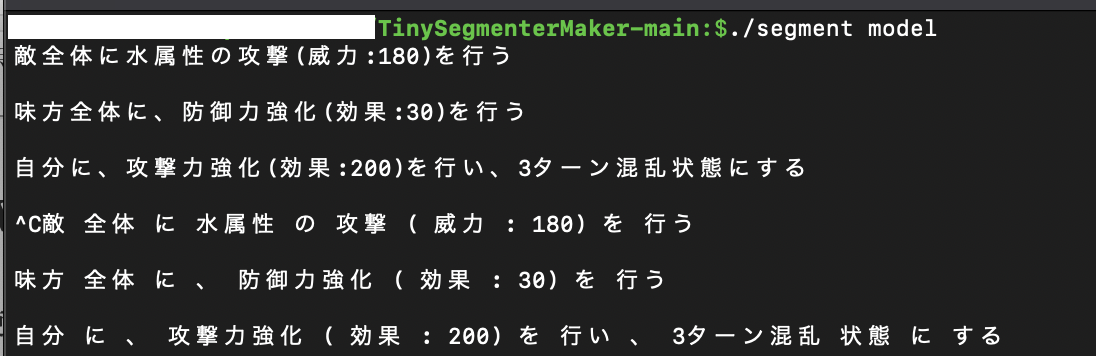 属性/の/攻撃/(/威力/:/180/)/を/行う/
属性/の/攻撃/(/威力/:/180/)/を/行う/
このように出力されれば成功です。
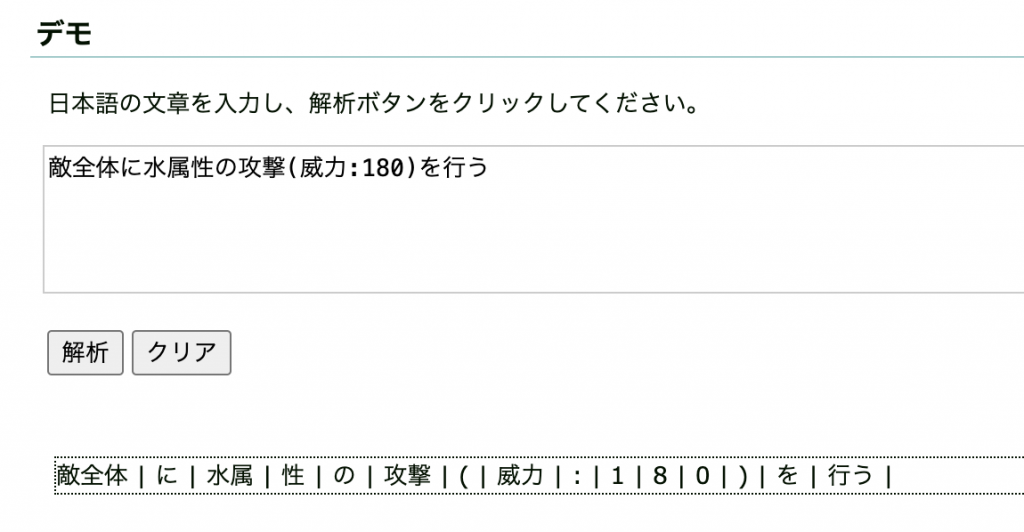
理想形とは結構違う出力がされてしまいました…
他の例文も試してみます。

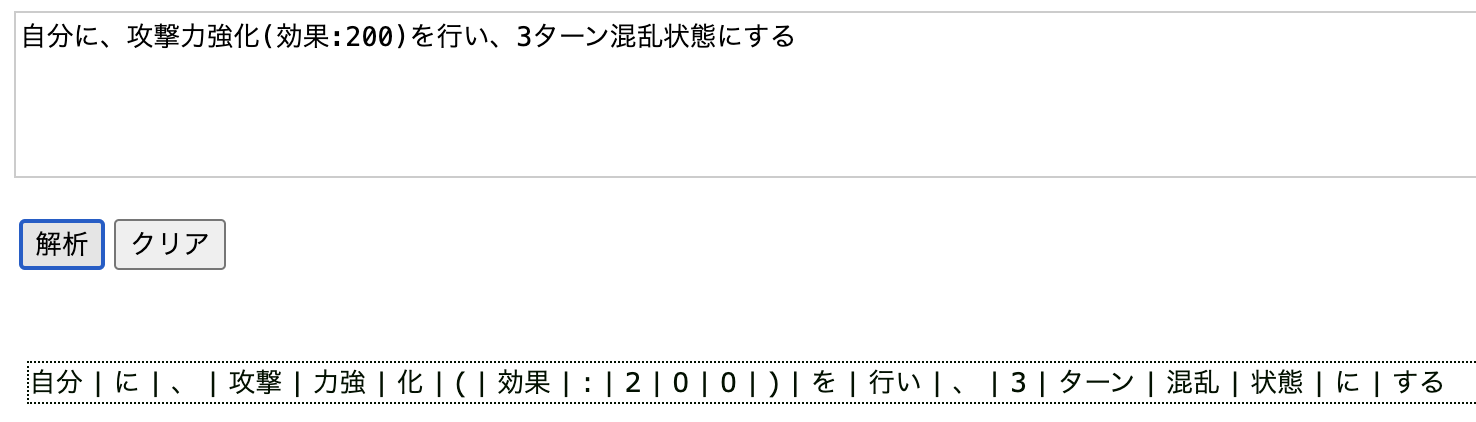
と、このようにかなり精度が低い状態です。
理由としては、こちらのライブラリは新聞記事を元に学習を行っているため、新聞記事とは全く異なるスキルの説明文はうまく対応ができません。
ですが、大丈夫です。
TinySegmenterには追加学習ができるツールが存在しています。
特化させるための追加学習
こちらのツールはTinySegmenter向けに作成された、モデルの追加学習ツールです。
使用方法としては、教師データとして事前にスペースで分かち書きを行ったファイルを用意し学習させます。
そのあとは、js用のモデルを出力させて、アプリケーションに組み込みます。
分かち書きのデータとしては、すでに存在しているスキルの説明文を130件ほど持ってきて、こちらが意図する分かち書きの形式で記述します。
|
1 2 3 |
敵 全体 に 、 水属性 の 攻撃 ( 威力 : 180 ) を 行う 味方 全体 に 、 防御力強化 ( 効果 : 30 ) を 行う 自分 に 、 攻撃力強化 ( 効果 : 200 ) を 行い 、 3 ターン 混乱 状態 にする |
これ以外にも、全てのパターンを網羅した方が良いので、
- 敵単体に、火属性の攻撃(威力:300)を行う
- 味方全体に、回復(効果:50)を行う
など、ユニークな説明文があればそれぞれ追加します。
学習方法についてはREADMEに書かれている通り、train.cppをコンパイルした上で実行を行います。
コンパイルにはc++コンパイラのg++が必要です。
|
1 2 |
$ g++ -O3 -o train train.cpp # コンパイル $ ./train -t 0.001 -n 10000 features.txt model # 学習 |
tarin.cppの処理では、機械学習の精度向上に使用されるAdaBoostを使用しているようです。
新しい弱分類器の分類精度が0.001以下,繰り返し回数が10000回以上が例として挙げられていたので、その通りに学習させてみます。
時間としては10秒程度で完了しました。
では学習させた後のモデルの実行結果です。
上3行が入力、下3行が分かち書きの結果になります。
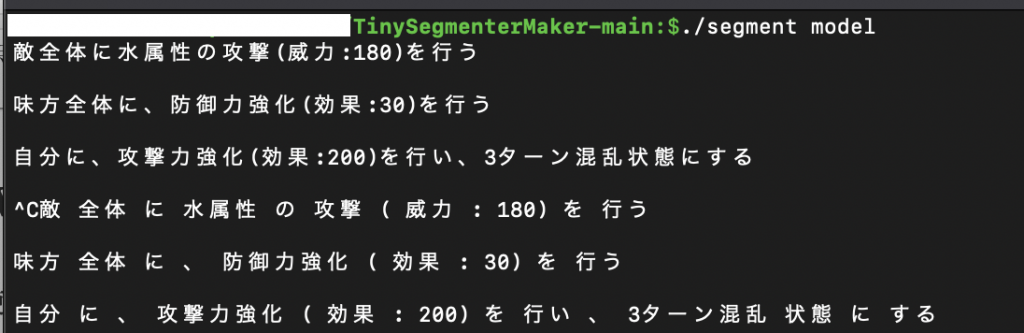
ほぼ正確に意図通りの分かち書きを出力できました!
(教師データが少し異なるので、効果値の後の)が分解できていないようです)
試しに全く学習させていない説明文も入力してみます。
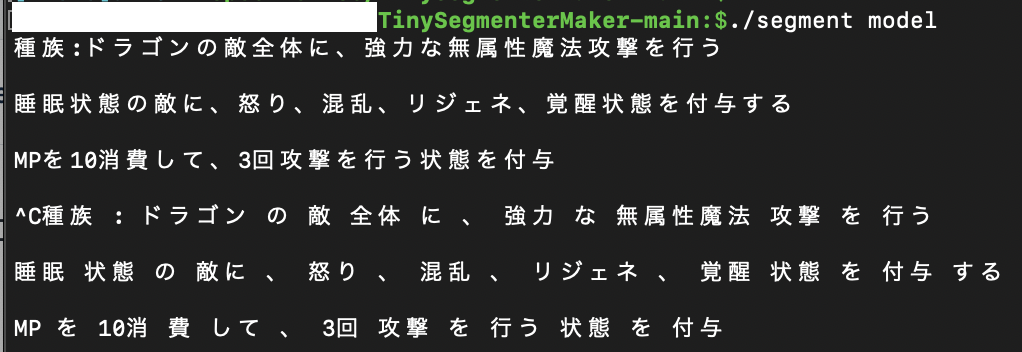
かなり綺麗に分かち書きすることができました!
あとは、モデルをjsで読み込める形式に出力します。
TinySegmenterMakerでは学習したモデルについてgoやpython, perlなど様々な言語への出力のサポートを行っています。
実行方法は下記のようにすると、JavaScriptでの出力を行ってくれます。
|
1 |
$ ./maker javascript < model |
出力されたものの一部がこちららです。
default_model変数に入っているものが、追加学習後のモデルとなっているようです。(こちらは長すぎるため省略しています)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
// (c) 2008 Taku Kudo <taku@chasen.org> // TinySegmenter is freely distributable under the terms of a new BSD licence. // For details, see http://chasen.org/~taku/software/TinySegmenter/LICENCE.txt (function(global) { global.TinySegmenter = TinySegmenter; var default_model = {BC1:{HH:5253,HI:2079,II:-3544},BC2:{AA:-24580,HH:-9983,HO:26391,IH:2786,....}; function TinySegmenter(model) { this.model = model || default_model; } var patterns = { "[一二三四五六七八九十百千万億兆]":"M", "[一-龠々〆ヵヶ]":"H", "[ぁ-ん]":"I", "[ァ-ヴーア-ン゙ー]":"K", "[a-zA-Za-zA-Z]":"A", "[0-90-9]":"N" }; var chartype = []; for (var i in patterns) { var regexp = new RegExp; regexp.compile(i); chartype.push([regexp, patterns[i]]); } function getctype(str) { for (var i in chartype) { if (str.match(chartype[i][0])) { return chartype[i][1]; } } return "O"; } |
Tauri側に組み込む
分かち書きのモデルを特化することができたので、いよいよtauriのフロントエンドに組み込みます。
しかし、tauriのプロジェクトに配置して実行できれば良かったのですが、先ほど出力された形式に問題がありました。
|
1 2 3 4 |
(function(global) { global.TinySegmenter = TinySegmenter; // 処理 })(<span class="hljs-variable language_">this</span>); |
具体的にはこの書き方で、こちらは即時関数での書き方かつgrobalに追加しています。
これはTinySegmenterMakerが古いプロジェクトのため、tauriで読み込める書き方と合わなかったということが考えられます。
そこで、下のようにJavaScriptのモジュールとして定義しimportする形で読み込むようにしました。
|
1 2 3 |
export const TinySegmenter = function() { // 処理 } |
|
1 2 3 4 |
import { TinySegmenter } from "./TinySegmenter.js"; const tinySegmenter = new TinySegmenter(); const segments = tinySegmenter.segment(description); |
importしたあとは、インスタンスを生成し、segment関数に説明文を入力すると、分かち書きで分割されたarray型で返ってきます。
最後に、前編でも紹介した通りrustのバックエンド側に分かち書きされたarrayを渡し、説明文と対になっているマスタの値を返してもらうことで、説明文からマスタの値に変換を行うことができました!
あとがき
今回rustとtauriを使うのが初めてだったのですが、今までとかなり異なる言語だったため、新鮮だったと同時にかなり苦戦しました。(笑)
特にrustは型付けがかなり厳密で、今まで通ってきたどの言語とも異なる書き方だったため、最初は思ったように記述できずずっとコンパイルエラーに頭を悩ませていました。
tauriについては、まだまだバージョンアップが続いていて、最近v2が出たということでこれからも使っていきたいと思いました!
ここまで閲覧していただきありがとうございました!


