
目次
はじめに
10ANTZではアーティストを起用したゲームタイトルを数多く開発、運用してきました。その中で我々バックエンドエンジニアはファンの熱量を強く感じる瞬間が多くあります。具体的にはサーバへのアクセス量であったりDBへの大量の書き込みだったり様々なシーンで頭を悩まされその凄さを感じてきました。この記事では、前述したDBへの負荷にフォーカスした取組について記載します。
背景
タイトルでも書いたとおり「運用中ゲームタイトルにCloud Spanner導入してみた」理由ですが、10ANTZのゲームタイトルは、定期的なイベント開催を軸に運用しているものが多いです。
その中でダントツの人気を誇るのが通称「彼氏イベント」と呼ばれるイベントで、イベント終盤ではDBへの負荷が通常時の倍以上に跳ね上がることがしばしばありました。(倍どころではないですが・・・)
10ANTZではAmazon Aurora(以下「Aurora」という。)を採用したタイトルが多いのですが、イベント終盤の負荷のためにスペックの良いインスタンスタイプを採用しているとコスト面を考えると無駄があるように感じていました。もちろんイベント前にインスタンスタイプを変更する手段もありますが、その都度メンテナンスに入れるのは運用として現実的ではありませんでした。そこでイベントの負荷のみを、また、高負荷に耐え得る代替サービスはないかと調べるうち、Cloud Spanner(以下「Spanner」という。)を見つけ思いきって導入することを決めました。しかしながら、運用中のゲームタイトルに途中からSpannerを導入するには、いくつか解決しなければならない問題がありましたので、それらに関して後述していきます。
Cloud Spannerについて
導入話の前にSpannerに関して簡単な説明をします。SpannerはGoogle Cloud Platform(GCP)で利用可能なDBサービスです。近年では、ゲームタイトルに導入されている例も多く、注目されているGCPサ−ビスのひとつと言え、現在もSpannerサービス自体はアップデートされ続けています。Spannerにはいくつかの特徴がありますが、今回の導入目的として、一番注目したのは「制限なしで必要に応じてスケーリング」できる点です。(その他の特徴は参考サイト1からご確認ください)
これまでのRDBMSではCAP定理を理由に、トランザクション処理と大規模分散処理は両立しないとされてきましたが、Spannerのスケーリング機能は分散処理しながら独自のTrueTime APIを用いたトランザクション処理を行うことで、データの一貫性を実現しており、まさに夢のRDBMSとなっている。(からくりは参考サイト3からご確認ください)
導入してみた
Spanner導入するにあたり多くの課題があった訳ですが、その中から今回はいくつか紹介したいと思います。
1.SpannerはAutoIncrementが使えない
みなさんが現在運用しているサービスで使用されているDBではAutoIncrementされたシーケンシャルなIDをPrimaryKey(以下「PK」という。)として割り当てたテーブルを使用することが多いのではないでしょうか?SpannerではこのようなシーケンシャルなPKが割り当てられているとホットスポットという問題が発生してしまいます。
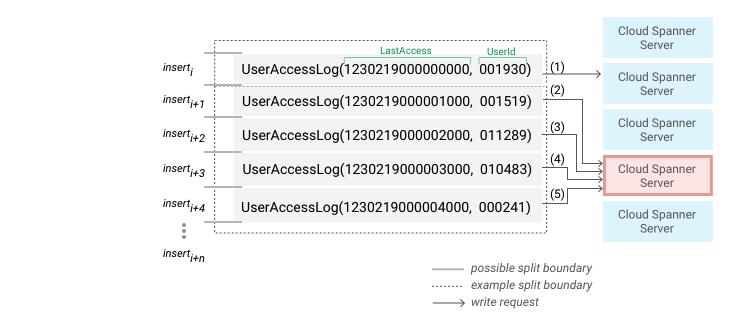
SpannerではPKを元にレコードが並べられており、それらがスプリットと呼ばれる分散ストレージに分割されて 各ノードに割り当てられています。シーケンシャルなPKを利用すると新しいレコードは必然的に最後のスプリットに追加されてしまい、特定のノードへ負荷が集中してしまいます。これがホットスポットと呼ばれる現象です(右図)。これでは負荷分散できないことがわかりますね。
弊社のタイトルも例外でなく、シーケンシャルなPKが割り振られたテーブルがほとんどで、テーブルをそのままのSpannerに持っていくことはできませんでした。そこで既存のテーブルにシーケンシャル出ないPKを追加し、この問題を解決しました。
例えば、ユーザ管理テーブルであればユーザIDがシーケンシャルなPKとして扱われることが多いと思いますが、そこに公式のベストプラクティスであるVer4のUniversally Unique Identifier(UUID)で発行したIDをPKとして追加することでホットスポットの発生を防ぐことができます。
このようにSpannerを利用する場合はスキーマ設計のベストプラクティスに近づけるように課題をつぶしていくことが必須となります。
2.フレームワークがCloud Spanner未対応
今回のミッションで一番の課題だったのがこちらになります。Spanner導入予定のタイトルはPHPで実装されており、フレームワークはPhalconを使用していました。お察しの通りPhalconはSpannerに対応しておらず、Spanner対応用のドライバのようなものが必要でした。ちなみに当時、コロプラさんがLaravelのSpanner用ドライバを公開されていました。(なんでウチはPhalconなんだ。。。)
すでにSpanner導入に舵を切っていたこともあり、弊社では、Spanner用のPhalcon ORMを作成し対応することにしました。ORMを作成するにあたり、SELECT/DML/DDLステートメントが発行できるよう独自のクラスを作成し、それらをORM内で継承することでPhalconからSpannerを利用できるような設計を目指しました。
Githubを公開していないためオープンにはできないのですが、基本的にはSpannerとの接続を行うクラス、Interfaceで実装されている関数に対して、DBサービスに応じてオーバライドできるクラス、Spannerからの戻り値を\Phalcon\Mvc\Model\Resultset\Simpleに格納するクラスの3つを実装するところが一番の肝となります。
3.InterleaveとForeignKeyに気をつけよう
これは課題というわけではないですが、注意すべき事柄だったという点で記述します。SpannerにはInterleaveとForeignKeyと呼ばれる概念が存在し、どちらもテーブルの親子関係を定義する方法なのですが、Interleaveは親テーブルの主キー列が子テーブルの主キーに含まれる親子関係。ForeignKeyはより一般的な親子ソリューションでありMySQLの外部キー制約のようなものと考えてもらうとわかりやすいと思います。それぞれ例を示し、違いや注意点を紹介します。
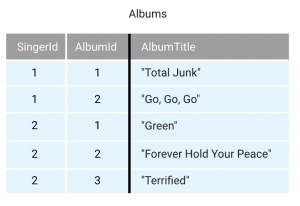
・Interleaveされたテーブル例
| DDL |
イメージ |
||
|
|
・ForeignKeyが定義されたテーブル例
|
1 2 3 4 5 6 7 |
CREATE TABLE Orders ( OrderID INT64 NOT NULL, CustomerID INT64 NOT NULL, Quantity INT64 NOT NULL, ProductID INT64 NOT NULL, CONSTRAINT FK_CustomerOrder FOREIGN KEY (CustomerID) REFERENCES Customers (CustomerID) ) PRIMARY KEY (OrderID); |
上記DDLで作成した外部キー関係は、Orders テーブルと Customers テーブルの間に定義され、対応する顧客が存在しない限り、注文を作成できない制約ができる。
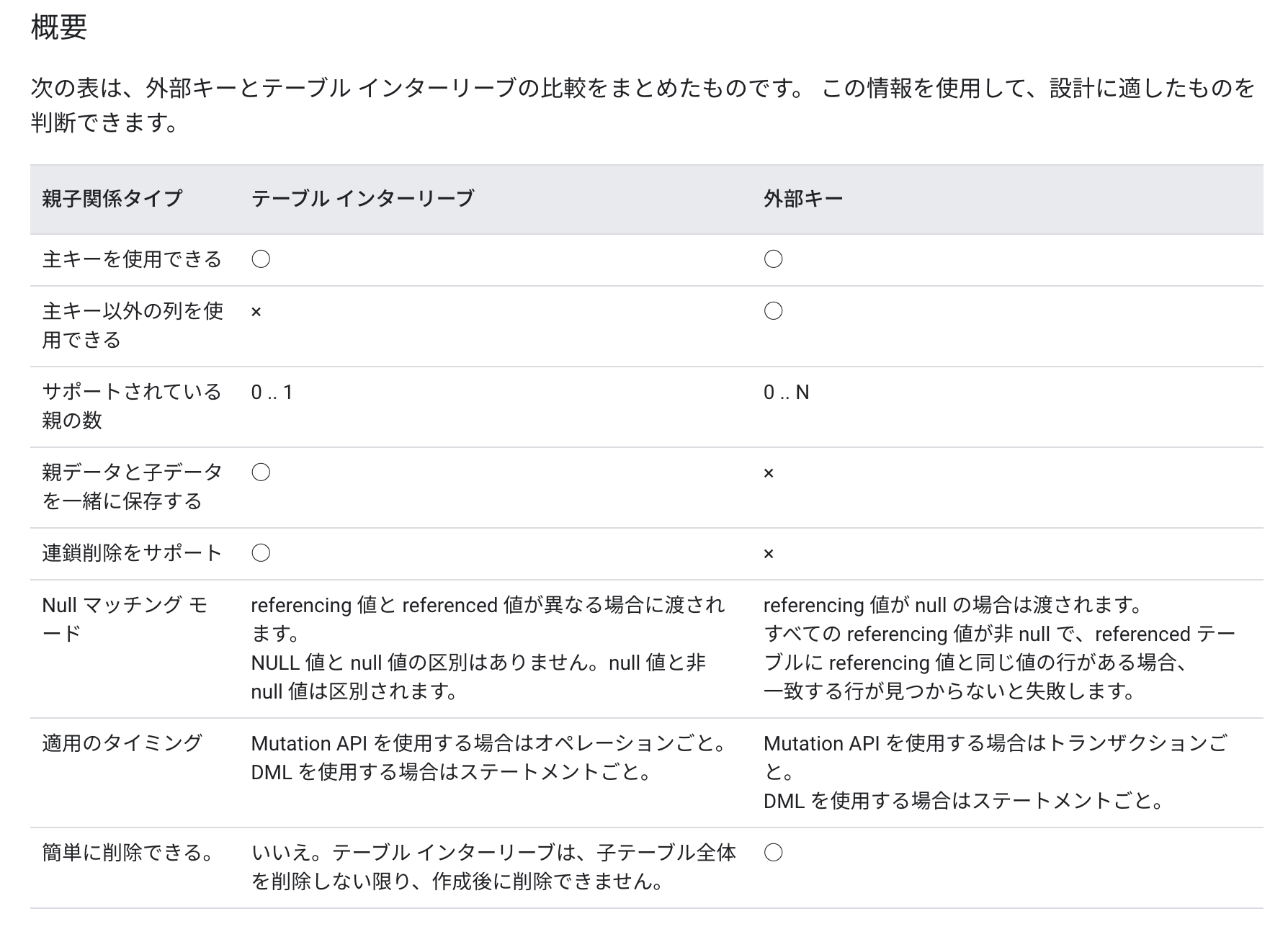
・InterleaveとForeignKeyの概要比較
https://cloud.google.com/spanner/docs/foreign-keys/overview?hl=ja#summary
・Indexにも注意
Interleave関係にあるuser、user_loginテーブルが存在した場合、親であるuserテーブルと同様のIndexはuser_loginには貼れません。また、子であるuser_loginテーブルに貼ってあるIndexと同じIndexを親のuserテーブルに貼るとuser_loginのIndexが外れます。この事象はIndexがテーブルで管理されているので「同名のIndexが貼れない」というわけではなく、両テーブルで「同じカラムで構成したIndex」は親にしか登録できないというものでした。これはInterleaveしているので、別テーブルだとしても、それぞれ同じカラムに見えているのだろうと解釈しています。
他にもForeignKeyを貼った場合、Spannerの設計上、実装者の意図しないIndexが内部的に貼られるので、MySQL感覚で設計してしまうと不要なIndexが大量に貼られ痛い目にあうかもしれません。これに関しては慣れもあるので、ぜひご自身で作成しながらINFORMATION_の各テーブルを確認すると面白いと思います。(情報スキーマに関しては参考サイト7へ)
4.トランザクションに注意
最後にトランザクションの注意点について記述します。
Spannerでは整合性を保つために読み取りと書き込みを行うトランザクションと読み取りのみを行うトランザクションが存在します。分散処理のパフォーマンスを最大限に活かすためにはこの2つのトランザクションを上手に使い分ける必要があります。ページ下部の参考サイト6の中でも記載されているように、Spanner の内部的なロック取得が他のトランザクションを abort することがある。ということを念頭に置きながら、
- 読み込みしか行わない所は Read-Only Transaction にすること
- Read-Write Transaction の中身はリトライされても問題のないよう冪等にすること
の2点に注意しながら実装を行うことが大切になります。
導入してみての感想
今回は「運用中のゲームタイトルのイベント機能のみSpannerへ移行する」ことをミッションに試行錯誤したわけですが、残念ながら導入したタイトルはDAUもかなり減少しており、Spannerの恩恵を厚く受けることはできませんでした。次にチャレンジする時はSpannerの凄さが感じられるような大規模プロジェクトで試してみたいですね。
また、Spannerの裏側ではいろいろな仕組みが隠れていて、表面上理解していてもSpannerのメリットの50%も得られないというのが率直な感想です。私自身もまだまだ理解しきれていない部分が多いですし、新しい機能もどんどん追加されているので、興味のある方は是非Spannerを使って試行錯誤したことを世の中に発信してほしいです!
最後に
10ANTZではアーティストとファンのつながりをテーマにサービスの開発、運用を行っています。その中で本記事で述べたような、ファンの熱量を肌で感じながらヒーヒー言っている運用を頑張っているエンジニアや、ユーザのプレイ動向を詳細に分析する分析エンジニア。また、新しい技術を取り込み既存のシステムでは実現できなかった問題の解決を試みるエンジニアなど、様々な角度から課題解決に務めるエンジニアが在籍しています。このテックブログを読んで少しでも興味を持っていただけると嬉しいですし、是非、他の記事にも目を通してほしいです。


