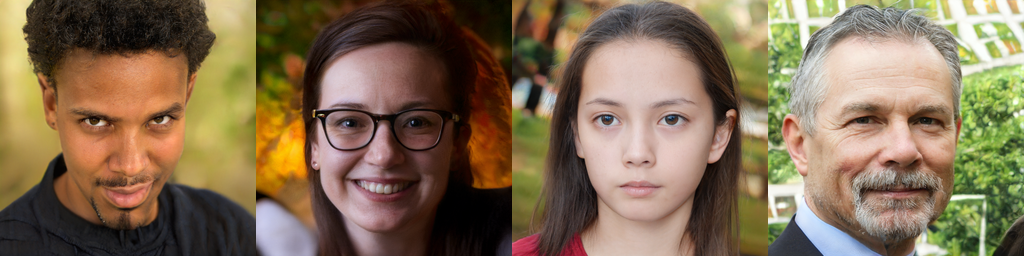
目次
はじめに
こんにちは、開発G所属のエンジニア楊銘です。
主にAI技術の開発と応用を研究しています。
この記事はGAN技術の研究について、理論からネットフレームワークまでと私たちの主な研究内容と成果を簡潔に紹介します。
GANとは
StyleGANを理解する前に、GANという概念を知る必要があります。
GANとはGenerative Adversarial Networksの略です。GANは教師なし学習で画像を生成するフレームワークで、
主にGeneratorとDiscriminatorこの二つのネットワークで構成されています。Generatorはノイズから画像を生成
します。DiscriminatorはGeneratorで生成した画像と本物の画像を見分けます。
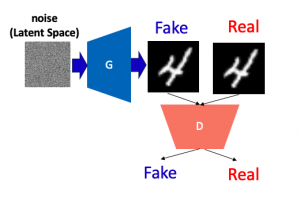
その後、生成された画像と実際の画像の差を減らすために、Generatorは独自のネットワークパラメータを調整し、
より正確な画像を生成します。また、Discriminatorも独自のパラメータを継続的に更新して、より正確に生成画像と
実際の画像を識別します。これはGANの核心:対抗という思想です。
![]()
GANの評価指標
–FID (Frechet Inception Distance)
FIDは、実際の画像の特徴ベクトルと生成された画像の間の距離を計算するための尺度です。FIDは、元の画像の
コンピュータービジョン機能の統計的類似性から、2セットの画像の類似性を測定します。この視覚的機能は、
Inceptionv3画像分類モデルを使用して計算されます。 スコアが低いほど、2セットの画像が類似しています。
最良の場合のFIDスコアは0.0です。これは、2セットの画像が同じであることを意味します。
–PPL (Perceptual Path Length)
PPLは、「知覚」的に、つまり我々の感覚で見て潜在空間上で画像が滑らかに変化するか、という指標です。
FIDと同様に学習済みモデルで埋め込まれる画像の距離を使います。ざっくり説明すると、「画像を生成す
る種となる潜在空間上で、画像の変化は『知覚的』に短距離で変化しているか」の指標です。
StyleGAN
GANに関する多くの研究の中で、最も有名なものはStyleGANです。これは、画像のさまざまな属性レベルで高品質で
高解像度の画像を生成できる、近年広く知られています。下の写真は、StyleGANテクノロジーを使用して生成された
高精度の顔を示しています。StyleGANのネットワークでは、Progressive Growingを用いた高解像画像生成、AdaINを
用いて各層に画像のStyleを取り込む、という2つの特徴があります。
Progressive Growing
Progresive Growingは有名なGAN研究を関する論文“Progressive Growing of GANs for Improved Quality, Stability,
and Variation”で提案された高解像度画像を生成する手法です。ざっくり言うと『低解像画像の生成から始め、徐々に
高解像用のGenerator,Discriminatorを追加していくことで高解像度画像を生成する手法』です。
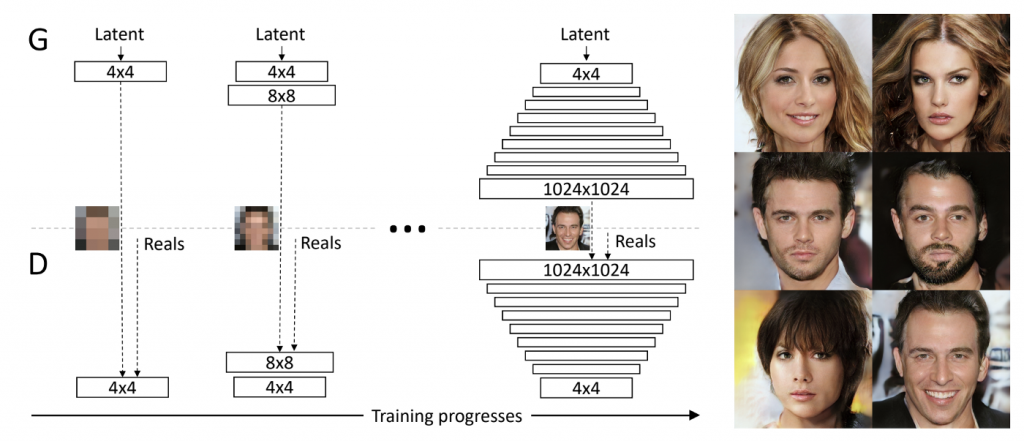
上の図では,4×4の画像生成から始め、徐々に解像度を上げて最終的には1024×1024の高解像度画像を生成しています。
AdaIN
AdaINはAdaptive Instance Normalizationの略で、Xun Huangらによって2017年に提案されたスタイル変換用の正規化
手法です。その主な目標は、リアルタイムの任意のスタイルスタイル転送(Style Transfer)を実現することです。主な方法
は、コンテンツ画像の特徴の平均値と分散値をスタイル画像の平均値と分散値に揃えることです。

このうち、µ(x)とσ(x)はそれぞれcontentイメージの特徴の平均値と標準偏差を表し、µ(y)とσ(y)はそれぞれstyleイメージの
特徴の平均値と標準偏差を表します。この公式は、まずスタイル化(自分の平均値を引いてから自分の標準偏差を割ります)
して、スタイルをスタイルイメージに変えます。
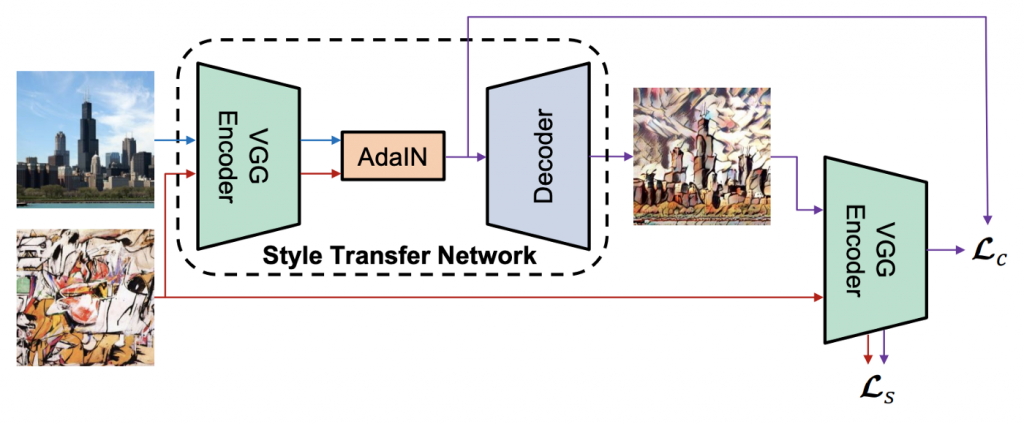
トレーニング中、最初にVGGを使用してコンテンツ画像とスタイル画像の特徴を抽出し、次にAdaINモジュールで操作し、
次にVGG対称デコーダーネットワークを使用して特徴を画像に復元し、復元された画像をVGGに入力して抽出します機能
とコンテンツの損失とスタイルの損失を計算し、スタイルの損失は複数のレイヤーの特性を計算します。 VGGのパラメーター
は、トレーニングプロセス中に更新されません。トレーニングの目的は、優れたデコーダーを取得することです。
StyleGANネットワーク構造
従来のGANネットワークアーキテクチャとスタイルベースのGANネットワークアーキテクチャの比較:
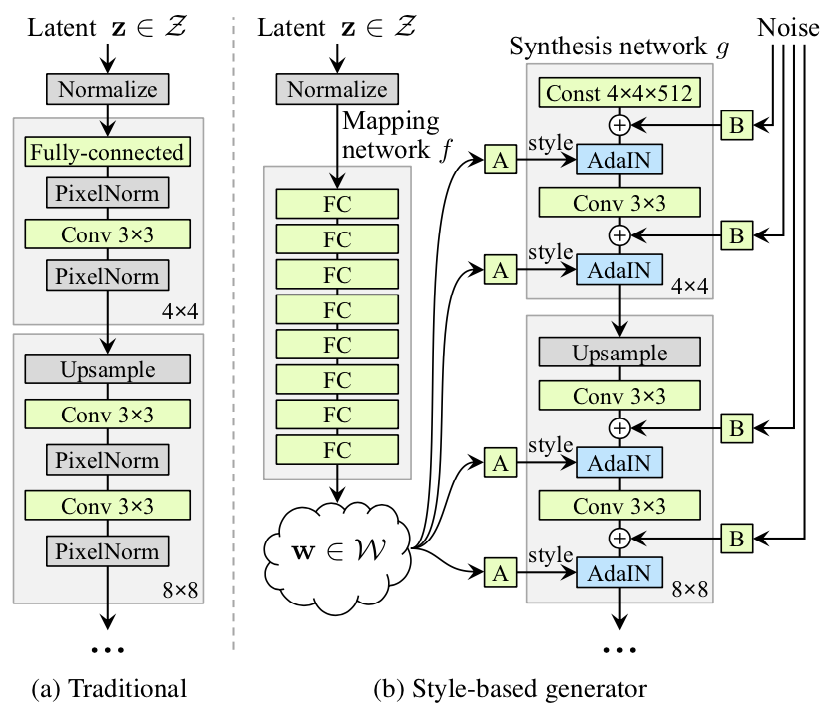
StyleGANネットワークは2つの部分で構成され、1つは左側のマッピングネットワーク(Mapping NetWork)、
もう1つは右側の合成ネットワークで、18層あり、各解像度には2つの畳み込み層(4、8、16 … 1024)を持ちます。
StyleGANネットワーク構造は主に以下のいくつかの特徴があります。
①従来の入力を削除する (Remove Traditional Input)
従来のGeneratorは、初期入力として潜在コード(ランダム入力)を使用します。StyleGANはこの設計を破棄し、
Generatorの初期入力として学習可能な定数を使用します。 1つの仮説は、特徴のエンタングルメントを減らすと
いうものです。ネットワークの場合、エンタングルされた入力ベクトルに依存する代わりに、wのみを使用する方
が学習が容易です。
②マッピングネットワーク (Mapping NetWork)
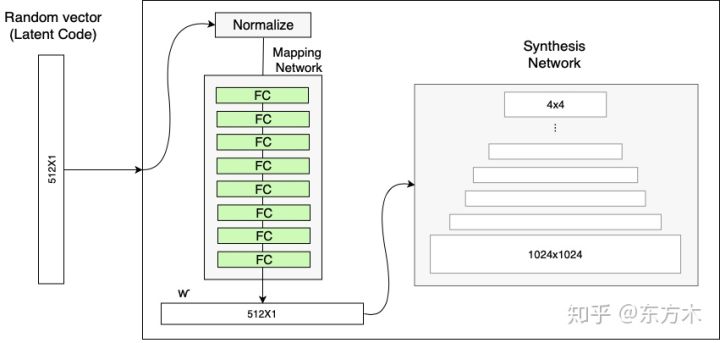
マッピングネットワークは完全に接続された8つの層で構成され、出力wは入力zと同じサイズ(512×1)です。
Mapping NetWorkの目標は、入力ベクトルを中間ベクトルにエンコードすることであり、中間ベクトルWの
さまざまな要素がさまざまな視覚的特徴を制御します。
③スタイルモジュール(スタイルモジュール、AdaIN)
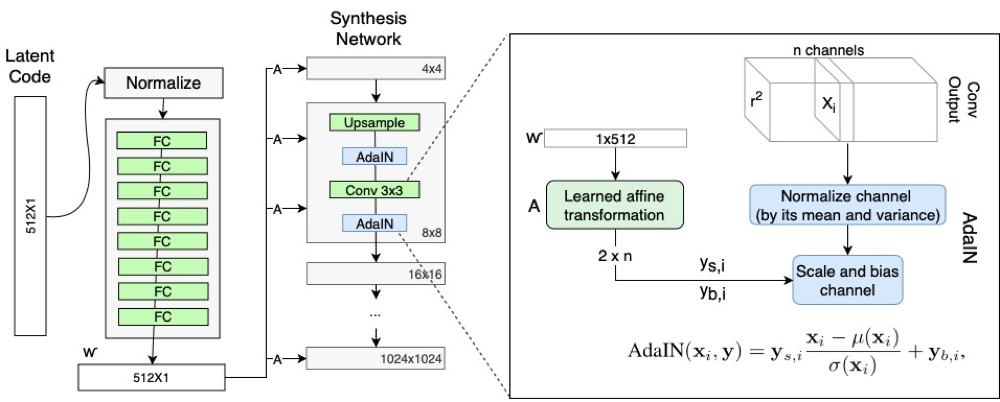
計算プロセス:
①まず、各フィーチャマップは個別に正規化されます。 フィーチャマップの各値は、フィーチャマップの平均から差し引かれ、分散で除算されます。
②学習可能なアフィン変換A。これは、wをAdaINの変換およびスケーリング係数yにスタイルで変換します。
③次に、スタイルで学習した平行移動とスケーリング係数を使用して、各フィーチャマップの縮尺と平行移動の変換を実行します。
④確率的変動(Stohastic variation、ノイズを追加することによってGeneratorのランダムな詳細を生成する)
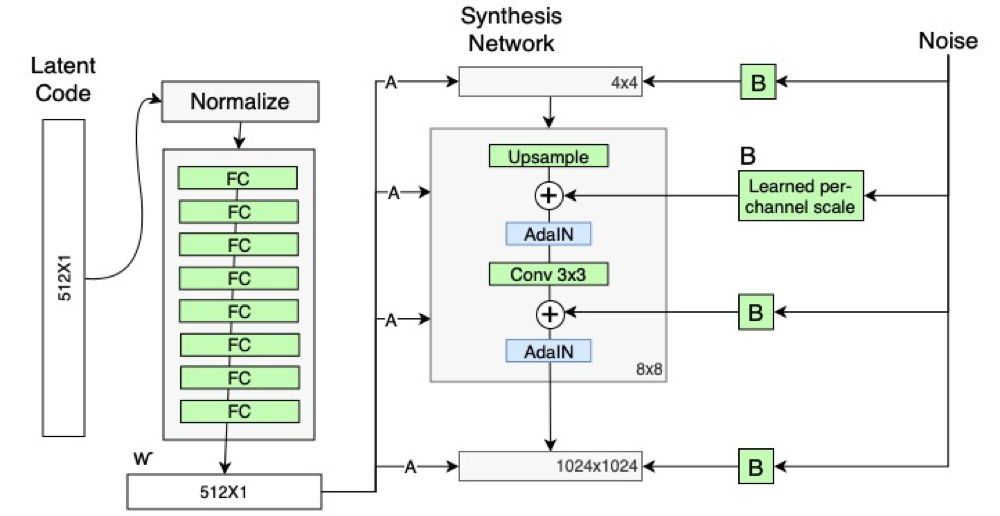
スケーリングされたガウスノイズは、合成ネットワークの各解像度レベルで追加され、合成ネットワークの機
能マップに提供されます。 畳み込み後、AdaINの前にガウスノイズがジェネレータネットワークに追加されま
す。 B学習可能なスケーリングパラメータを使用して入力ガウスノイズを変換し、ノイズ画像をすべての特徴
マップにブロードキャストします。
Mixing Regularization
異なるレイヤー間のスタイルの相関をさらに減らすために、StyleGANはジェネレーターにハイブリッド正則化を
使用します。
スタイルブレンディングを使用して、トレーニングサンプルの特定の割合の画像を生成します。 トレーニングプロ
セスでは、1つではなく2つの暗号コードzが使用されます。画像が生成されると、合成ネットワークでレイヤーが
ランダムに選択され、1つの暗号コードから別の暗号コードに切り替えられます。 具体的には、マッピングネット
ワークを介して2つの潜在コードz1とz2を実行し、対応するw1とw2にパターンを制御させて、w1が交差点の前に適
用され、w2が交差点の後に適用されるようにします。
StyleGAN2: StyleGAN改良
StyleGANは最初は美しい画像を生成することができましたが、これらの画像にはまだ不自然なものがいくつかあり
ます。例えば、下の図で発生している水滴のようなノイズ(droplet)について見ていきます。

次は特徴の一部が顔の動きに追随しないというモードです。例えば、顔が横向きに変化していっても歯並びが追随して
おらず、不自然になっています。ほかのいくつか不自然ところもあります。そして、StyleGAN2では、正規化の改善と
潜在空間を滑らかにする制約を加えることで画像の品質を向上させています。
私たちの主な研究内容と成果
実現原理とStyleGAN2ネットワークを学習した上で、私たち主にStyleGAN2を利用し、様々な研究をしました。
- 画像生成
- 顔の属性を編集
- フェイス融合
画像生成
Stylegan2の利点は、十分な数のカスタムデータセットがある場合、長期間のトレーニングの後、優れた画像ジェネレーターを
取得できることです。 比較的少量のデータセットでも、事前トレーニングモデルを微調整した後、良好な結果を得ること
ができます。以下のは、100枚未満のカスタムデータセットのみを使用して、トレーニングを微調整した後に得られた結果の写真
の一部です、かなりいい写真を生成しましたね。

顔の属性を編集
StyleGAN2ネットワークから得るzとwコードを編集することで、顔の属性を編集できます。
Age:

Gender:

Smile:

Pitch:

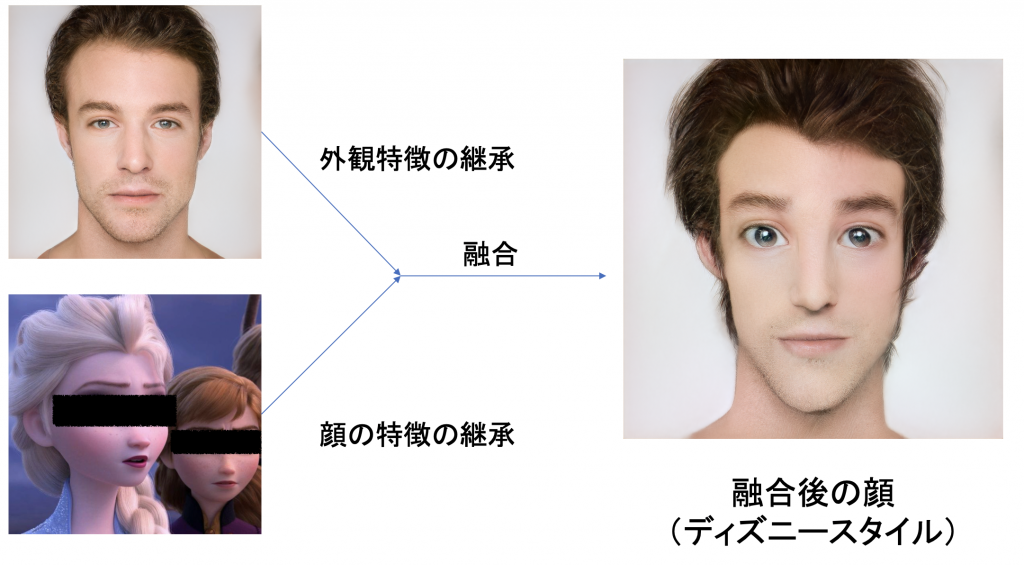
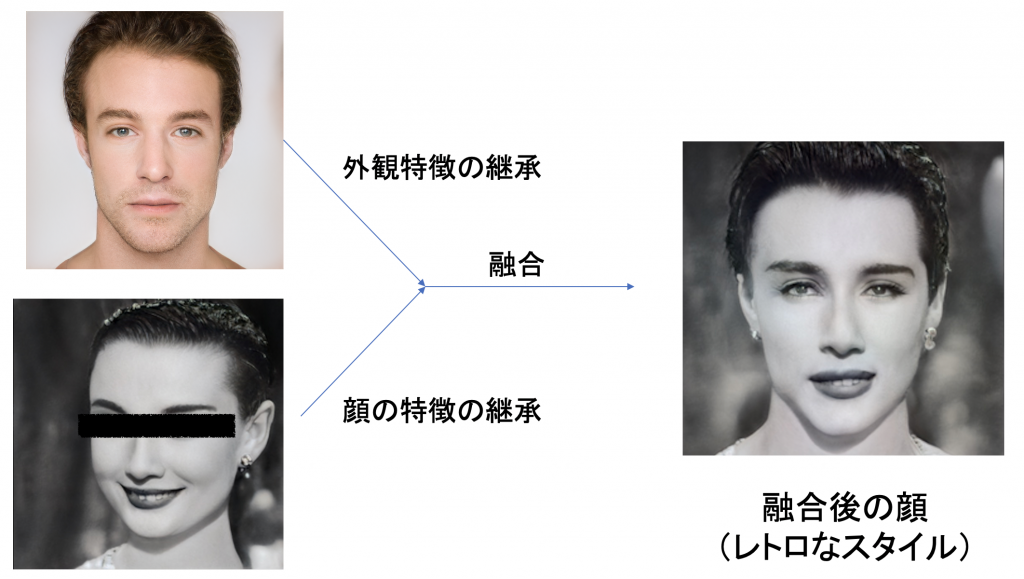
フェイス融合
画像の様々な特徴の隠しコードの表現を制御することが可能であるため、異なる層の隠しコードを交換して特徴の融合
を実現することが可能になる。
フェイス融合(ディズニースタイル):
フェイス融合(顔交換):
フェイスからアニメ風変換1:

フェイスからアニメ風変換2:

追記: 彼女生成とイケメン生成Webサイト作成
この前、WaifuLabというWebサイトを見ました。内容はとても面白くて、中身はGAN技術を使用して、主に色な女性ア
ニメキャラをランダム的に生成することができます。私がそれを見ると、その技術原理をすぐわかりました。そして
自分で同じような仕組みを持つWebサイトを実現しようと思いました。
自作イケメン生成Webサイトの展示
まずは自作のイケメン生成Webサイトがどう何ことをやるのか簡単に紹介します。サイトに実現したキャラ生成効果が四
つのスッテプになります:
スッテプ1:男性アニメキャラをランダム生成

ランダムで16個男性アニメキャラを生成します。その中に一つのキャラを選択して、次のスッテプへ移動します。
スッテプ2:画像の全体的なスタイルの調整

左で1個のキャラはスッテプ1で選んだキャラ、右の16個のキャラはスッテプ2で展示された異なる画風スタイル
を持つキャラ。その中からまだ好きな画風キャラを選択して、スッテプ3へ移動。こういう風にスッテプ4まで調整する。
スッテプ3:キャラの色(髪、目)調整
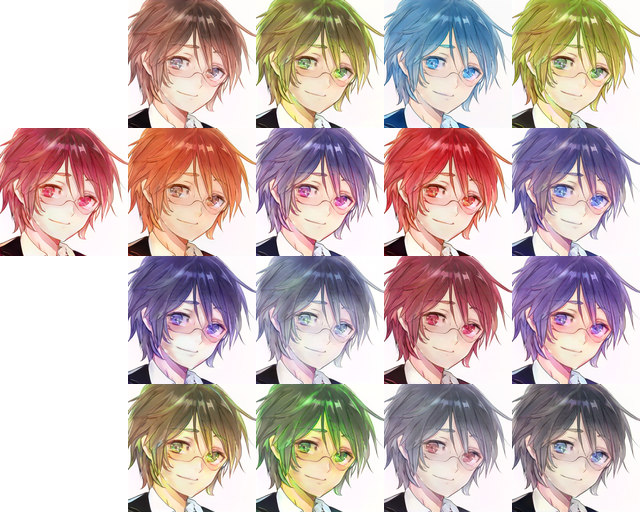
左の1個のキャラはスッテプ2で選んだキャラ、右はスッテプ3で展示された異なる色も持つキャラ。
このスッテプは主にキャラの色部分を調整します。
スッテプ4:キャラ顔の詳細な部分調整

同じく、左のはスッテプ3で選んだキャラ、右の16キャラはスッテプ4で展示された異なる顔詳細を持つキャラ。
顔のディテールを調整することで、写真にいろんなの感覚を与えることもできます。
Webサイト例:

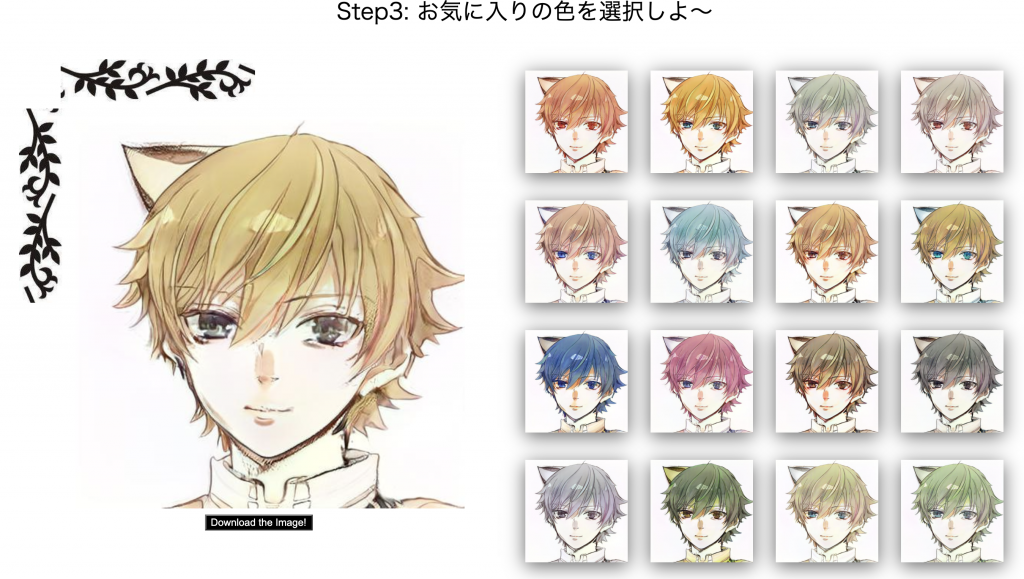
もちろん、スッテプ1からスッテプ4までのどの段階でも、選んだキャラをダウンロードすることができます、決し
て最後のスッテプ4まで進む必要がないので、とても便利です。
実現原理
生成された画像に対するこの一連の調整の実現に関して、原則は実際には画像の隠しコードの操作です。
前述のように、StylGANモデルは、生成された隠れ空間ベクトルを使用して、画像の生成を制御します。 つまり、
StyleGANによってトレーニングされた画像ジェネレーターの場合、生成された画像には対応する画像の隠しコード
があり、この隠しコードの空間次元はモデルのサイズによって決定されます。 一般的に、1024ピクセルの画像
生成モデルの場合、一つの画像には【1,18,512】サイズのTensor、つまり隠しコードがあります。それに
対して、512ピクセルの生成モデルは【1,16,512】サイズの隠しコードを持つ。これらの隠しコードに対
して、そのパラメータを調整することによって、異なる画像間の変換ができます。
「フロントエンドフレーム」と「バックエンドフレーム」:
今回は画像生成や各種ディテール調整機能を備えたウェブサイトを作ることを目的としているため、ウェブ側にディ
ープラーニングモデルを展開するという技術的要件も意味します。フロントエンドのウェブデザインだけではなく、
サーバ側ルーティング関数の論理性も設計することも必要、私にとって挑戦的な課題である。そしてここで今回を使
用したフロントエンドフレームとバックエンドフレームを紹介しようと思います。
1. フロントエンドフレーム:フロントエンド側に、WEBサイトの設計には主にHtmlとCssを使用して、中身はFlex
レイアウトも含まれています。そしていくつかの機能的な操作はJavaScriptに任せて解決します。バックエンドクラ
ウドサーバと非同期通信を行うために、Ajaxを使用して、データ間の交換を行うのは便利です。自分は元々AI開発研
究をメインにして、フロントエンドにあまり触らないので、ここまでやるのはかなり勉強しました。
2. バックエンドフレーム:まずは訓練されたモデルを安定的に動作させる環境を構築する必要があります。今回
はTensorFlow 1.14バッジョンのディープラーニングフレームワークを導入しています。そしてモデル予測結果をWebペ
ージ側のデータ像と結合するために、FlaskというWebアプリケーションフレームワークを使用しました。Webフレー
ムワークとは、ウェブサイトやウェブアプリケーションを作るための機能を提供し、ウェブフレームワークを使わない
時よりもより容易にWebアプリケーションを作ることができるものです。FlaskはPythonのWebアプリケーションフレ
ームワークで、小規模向けの簡単なWebアプリケーションを作るのに適しています。
Flaskフレームワークを使用して、ルーティング関数の設計が非常に重要です。その中で最も複雑な問題は論理だと思
います。 ルーティング関数間でのデータの共有を考慮するだけではなく、計算グラフに関連するグローバル変数も考
慮する必要があります。 毎回モデルをロードすることによる応答時間の長さなどの問題を防ぐために、Webページを
開く前に複数のモデルをプリロードする必要もあります。
今回の経験まとめ
今回の課題は、私にとって挑戦であり、貴重な経験でもあります。 自分で設計およびトレーニングしたモデルをサーバ
側で適切に展開する方法は、AI開発者にとって非常に重要なスキルです。もちろん今回実現したイケメン生成WEBサイ
トまだ色々欠点がありますが(データセットによって生成顔画像の品質まだ向上する余裕があると、Flaskだけを使うと
サーバの安全性が足りないなど)、その経験を積めて今後それ以上のレベルを目指することが大事だと思います。
最後に
GANはとても面白いAI技術です。それを利用して、自分が生成したい顔写真を自動できに生成すること
ができます。そして生成した物に対して、編集が可能です。興味ある方ぜひ試してください!
この記事の作成や一部画像は、以下の論文やサイトを参照しました。
Reference:
ProGAN: https://arxiv.org/abs/1710.10196
AdaIN: https://arxiv.org/abs/1703.06868
StyleGAN: https://arxiv.org/abs/1812.04948
StyleGAN2: https://arxiv.org/abs/1912.04958
WaifuLab: https://waifulabs.com/


