
インフラGのインフラエンジニアです。
監視システムをゼロから導入することになり、とりあえず色んな監視システムと出会ってみました。
かすれた名の方、白いカバみたいな方、ザビの付く赤い方、とても素敵な方々でしたが私の要件を満たすことはできませんでした。
目次
私の理想はどれも普通で1つでも妥協したくはありません
- 監視処理書きたくない。最初からパッと見たいところすべて吐いて欲しい
- 何十台のインスタンスがあっても導入楽なヤツがイイ
- 負荷ないとイイ
- ネットワークごとに監視専用サーバー入れたくない(金かかる)
- 異なるネットワークをまたいで監視して欲しい
- グラフを描画するサーバーを1つにしたい(異なるプロジェクトでも1つのドメインのWebサーバーでグラフ見たい)
- 1グラフで複数のインスタンスの負荷を見比べたい
- グラフの見栄えも操作も楽だとイイ(開発側でもグラフのクエリ書いて欲しい)
- もちろん閾値と通知もやって欲しい
- 監視ログは安価なストレージ(S3とか)に保存して欲しい
- インスタンスが入れ替わっても、同じホスト名/ラベル名で新旧をグラフで見比べたい
まだ色々あるけど、ひとまずこれ全部満たして欲しい。
そしてある日、Thanosと出会いました。
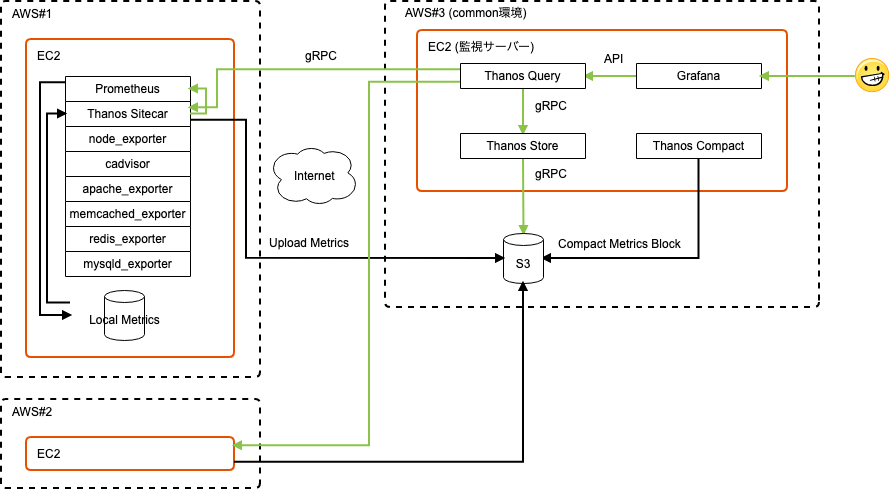
Thanosのアーキテクチャー
私的にはメトリクス収集とグラフ化のクエリは以下のように見えました。
グラフで描画したい時間帯のメトリクスごと、クエリ通信が分けられてるのがイイ!!(マイクロサービス様様です)
| 構成要素 | 説明 |
|---|---|
| Docker | 各ミドルをコンテナで起動させる |
| Promethus | 監視のコア(コンテナ起動) |
| node_exporter | サーバーリソースを監視(推奨に沿ってデーモン起動) |
| cAdvisor | コンテナを監視(コンテナ起動) |
| Thanos
thanos-compact thanos-query thanos-rule thanos-sidecar thanos-store |
メトリクスを分散オブジェクトストレージに保管
(コンテナ起動) (コンテナ起動) (コンテナ起動) (コンテナ起動) (コンテナ起動) |
| Grafana | メトリクスをグラフ化(コンテナ起動)
閾値でアラート通知 |
| S3 | メトリクスを保存 |
ここでのThanosサーバーは以下の構成です。
「thanos-compact + thanos-query + thanos-store + Grafana 」
それと自分自身も監視するので「Prometheus + node_exporter + cAdvisor + thanos-sidecar」もです。
今回は検証と言うこともあり手っ取り早く1つのEC2上で複数Thanosコンテナを起動させてます。
所感
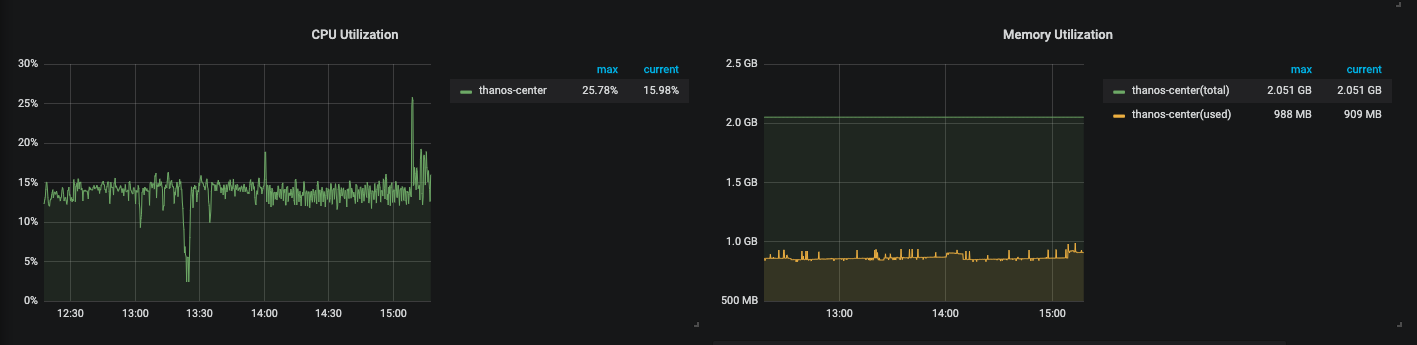
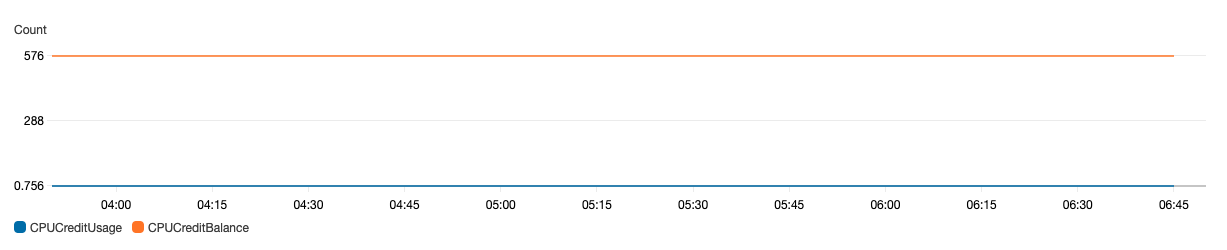
Thanosサーバーは1台のt3.smallで20台ほどのEC2インスタンスを監視してますが特に目立った負荷もなく安定運用しています。
CPU使用率、メモリ使用率。
ロードアベレージ

CPUクレジット
障害事例
マイクロサービスの利点を生かし費用削減の為に1サーバー(EC2)に複数コンテナを同居させてました。
コンテナと費用削減の特有の障害が発生しました。
- 同居させているので、あっという間にDockerイメージが肥大になりディスクを枯渇してしまった
- 同居させているので、ちょっとした作業障害の影響度が大きくサーバー負荷で共倒れしてしまった
→デプロイ時にサーバー負荷も見るような仕組みを入れるのも手かもしれません(例、デプロイ内にAPIでPrometheusメトリクスを確認する処理をするとか)
- thanos-queryとthanos-compactなど同居させてたので、thanos-compactが最適化を開始したタイミングでCPU負荷100%になり不通になってしまった
→常時処理するマイクロサービスとスケジュールなど限られたタイミングで処理するマイクロサービスは同居させない方が無難と思います
まとめ
そもそもコンテナ運用しやすいサービスを選択する重要性が分かった感じがしました。(Fargateなど)
参考サイト
Prometheus
https://prometheus.io/
node_exporter
https://github.com/prometheus/node_exporter
Thanos
https://github.com/thanos-io/thanos
cAdvisor
https://github.com/google/cadvisor


