
目次
はじめに
これからGCP基盤でプロジェクトの各種開発を進めるということで、データ分析基盤もそれに対応することになりました。
既存のTreasure Data基盤の分析環境がある中で、Bigqueryに乗り換えるかどうかの判断が必要になります。
その際、分析グループで考慮したことをまとめて紹介していきたいと思います。
背景
元々はtd-agentをアプリ側につけてロギングを行っておりましたが、
cloud runでのアプリ開発において今時点ではサイドカーコンテナ非対応なためtd-agentの配置が困難とのことでした。
ということで、新たなロギングアプリによるパイプラインの導入を検討することになりました。
多くの社内BIインフラに高いリアルタイム性が求められているという点が、悩ましい要件の一つでした。
パイプライン例
DBを引き続きTreasure Data(TD)にする場合
この場合、直接TD側に転送するオプションがなく、間にgoogle compute engineを挟む形になる状況でした。
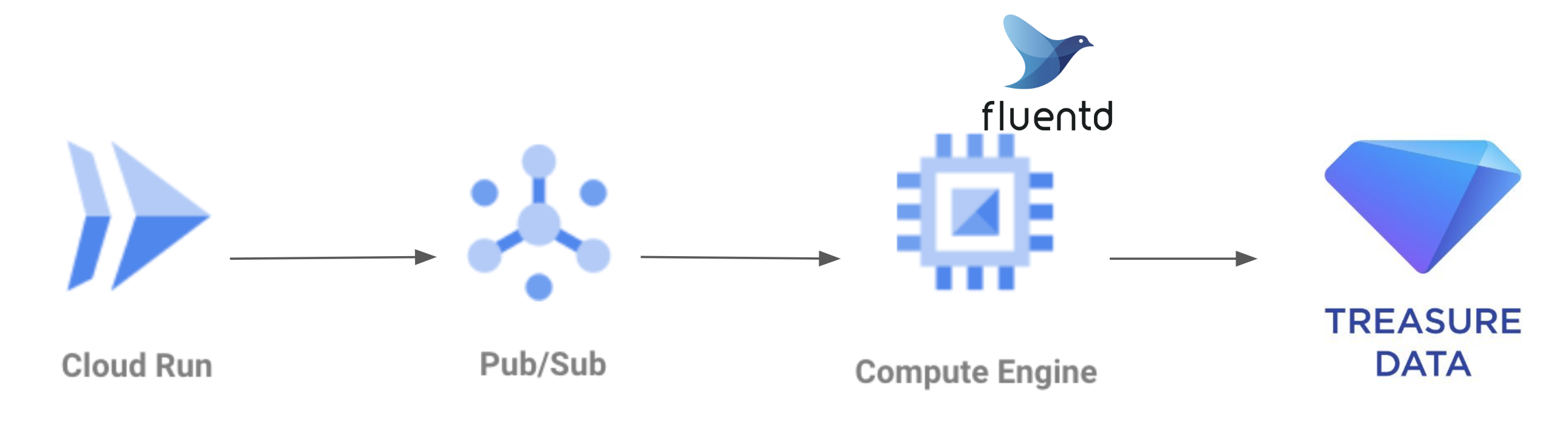
既存の社内BIインフラの資材をほぼ変えることなく使える場合が多いというメリットはありますが、
GCEが入って費用と運用工数がかかるというデメリットがあるものになります。
DBをBigqueryにする場合
次に、GCPならではのbigqueryを利用する場合です。
pub/subとDataflowの構成
この場合、よく使われている構成としてGCPのメッセージングサービスであるpub/subと、ETLサービスであるDataflowを繋げる構成があります。

定番の構成であるメリットがある反面、
高いリアルタイム性を保とうとしてstreaming insertで行くと費用・運用コストがかかるというデメリットがあるものでした。
Cloud Loggingのbigquery sinkを使って直接Bigqueryへ転送する構成
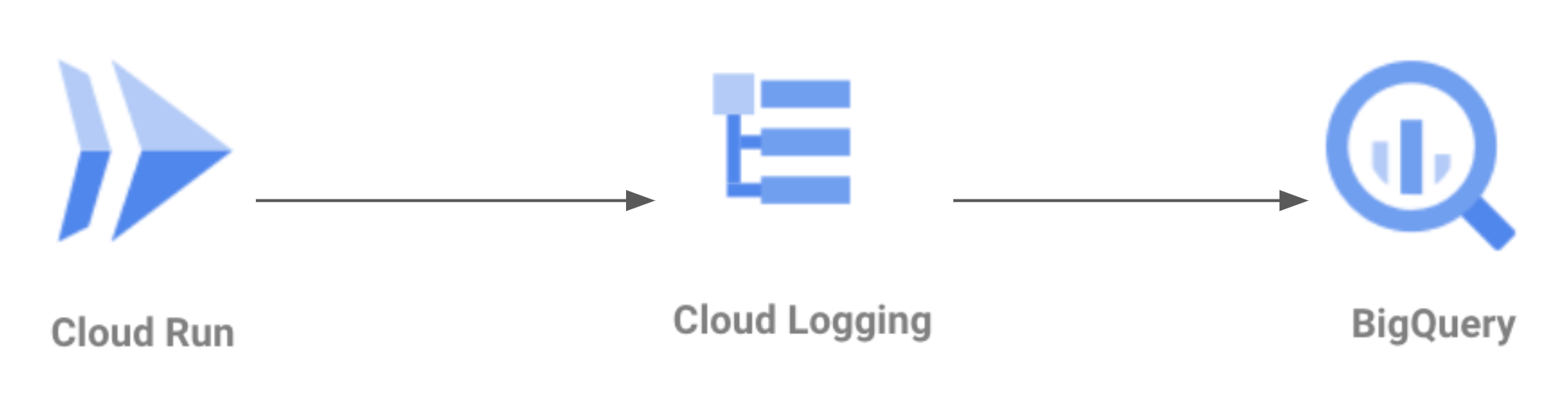
そこで、そのデメリットを補うべくCloud LoggingからBigqueryに直接送信する案がありました。
しかし、Cloud Loggingから送信する際の設定の自由度が低く、ゲームログのパイプラインとしては難しい結論でした。
そこでGCP側の方とやりとりしている中、最近(7月25日らしいです)公開された構成としてpub/subから直接Bigqueryに転送する機能が実装されたという話が出てきました。
pub/subのbigquery subscriptionを使って直接Bigqueryへ転送する構成
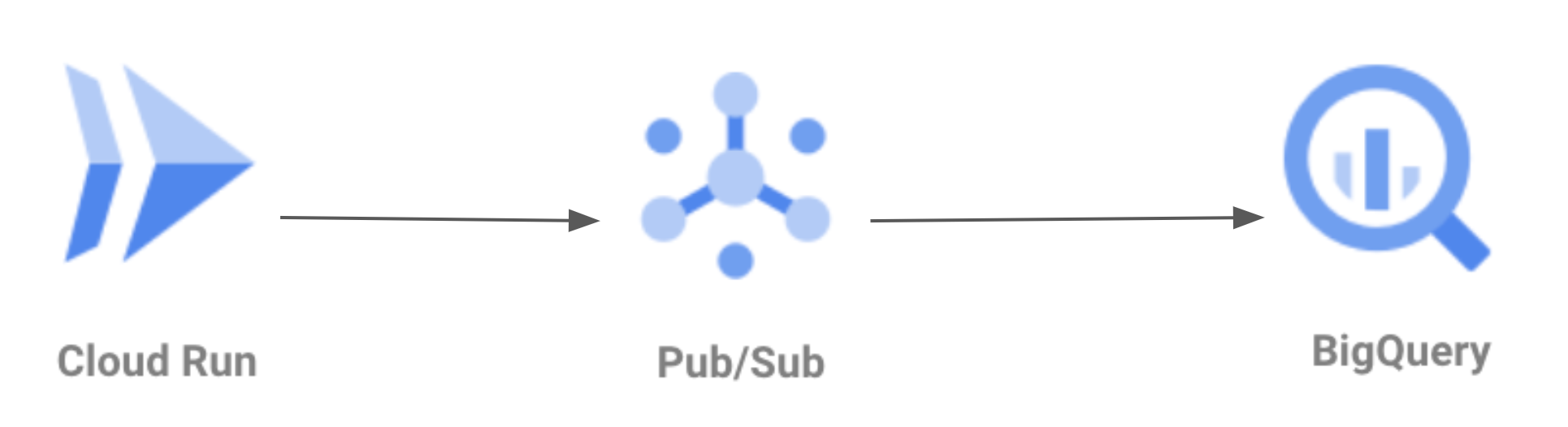
上記の3.2.1と比べてコンポーネントも減り、転送量のみで決まるコスト制になることがメリットで、リアルタイム性も満たしていました。
一方でDataflowのbeamコーディングにより可能となる処理のカスタマイズがここでは難しくなるのがデメリットの一つとして挙げられます。
判断の軸
上記4パターンに対し、維持管理・導入・運用の軸でコストの比較をしました。
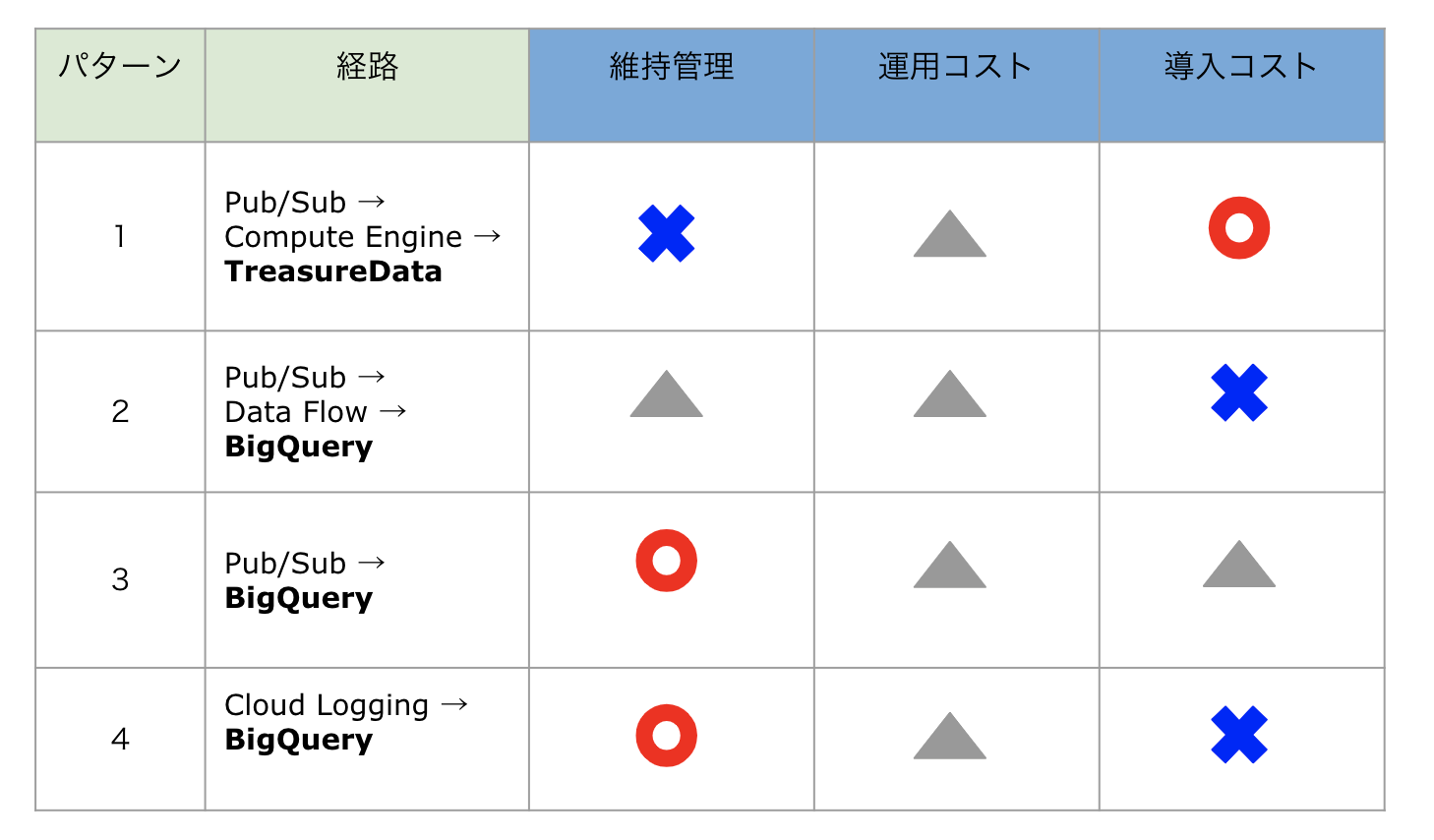
結論とこれから
案4はcloud loggingの自由度の問題で不採用とし、維持管理を重視するということで案3の選択肢を選びました。
導入コストの工数は将来を見据えて考えるとかける価値があるという考えです。
pub/subの新機能ということで重複対策が必要になるなどといった懸念点があり、これから対応していくことになります。
treasure dataもbigqueryもアプリ側からそれ以降の多くがGUIで済むということで、ここ2〜3年の間で構築がかなり親切なったと感じました。


