ディープラーニングという単語が世間一般に知られるようになったのは、2016年に登場した「AlphaGo(アルファ碁)」という囲碁AIがプロ棋士を破ってからではないでしょうか。AlphaGoは、Google DeepMindによって開発されたコンピュータ囲碁プログラム。プロの囲碁棋士を相手にした対戦で勝利を収め、大きな話題となった。

実はAlphaGoはディープラーニングと強化学習を組み合わせた「深層強化学習」という技術を使われています。
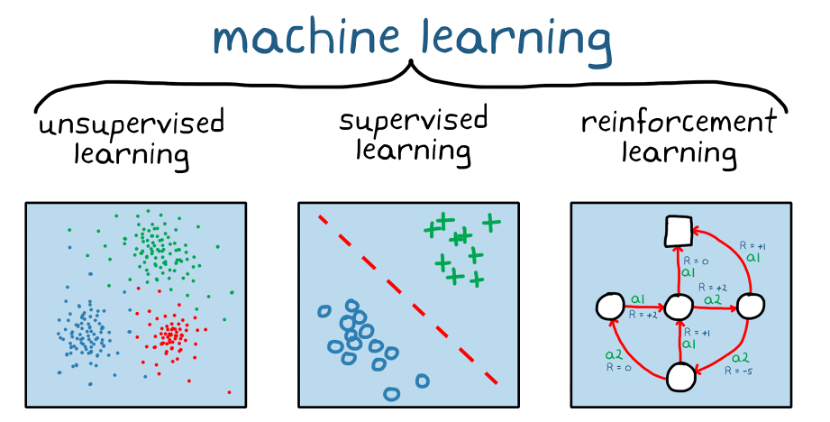
強化学習は機械学習手法の一つです。機械学習は大きく3つのタイプに分かれます: 教師なし学習、教師あり学習、強化学習。
- 教師あり学習: 入力と入力に対する正しい出力(正解データ)が与えられ、出力が正解データに近づくように学習する
- 教師なし学習: 入力のみが与えられ正解データは与えられず、データのパターンなどを学習し分析する
- 強化学習: AI自身が与えられた環境下で試行を繰り返し、報酬が最大となるように学習する
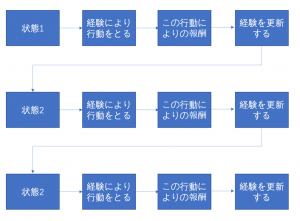
強化学習は静的なデータセットに依存せず、動的な環境で動作し、収集した経験から学習します。具体的な手法は、プログラム自体が与えられた環境(=現在の状態)を観測し、連続した一連の行動の結果、価値が最大化する(=報酬が最も多く得られる)行動を自ら学習し、選択していくだけでなく、行動についての評価も自ら更新していきます。
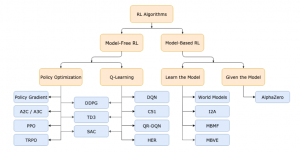
強化学習アルゴリズムには2つの主要なカテゴリがあります。 2つのカテゴリの重要な違いは、エージェントがその環境のモデルを完全に理解または学習できるかどうかです。
モデルベース(Model-Based)は環境に関する高度な知識を持っており、事前に計画を検討することができますが、モデルが現実の世界と矛盾している場合、実際の使用シナリオではうまく機能しないという欠点があります。
モデルフリー学習(Model-Free)は、前者ほど効率的ではないモデル学習を放棄しますが、この方法は実装が簡単で、実際のシナリオで良好な状態に調整するのは簡単です。 したがって、モデルフリーの学習方法はより一般的であり、より広く開発され、テストされています。
強化学習は囲碁に限らずさまざまな分野に応用できます、例えば自動運転、ロボット、ゲーム。より多くの分野(仮想シーンと実シーン)での強化学習の大規模な実装を楽しみにしています。


